آموزش کامل دستور SELECT در SQL
بخش مهمی از نرمافزارها و سایتهای اینترنتی، بخش ارتباط با پایگاه داده است و پرکاربردترین دستور که برای خواندن اطلاعات استفاده میشود، دستور SELECT نام دارد.
در این نوشته به مهمترین کاربردهای SELECT شامل خواندن اطلاعات از یک جدول و همچنین انواع مختلف JOIN ها خواهیم پرداخت.

نرمافزارهای مختلف پایگاه داده مثل MySQL و SQL Server و Oracle هر یک برخی تفاوتهای جزئی در دستورات دارند. حتی ممکن است نگارشهای مختلف یک نرمافزار هم تفاوتهایی جزئی در شکل نوشتن دستورات داشته باشد به همین دلیل به ویژه برای نوشتن دستورات پیشرفتهتر لازم است تا به مستندات مربوط به پایگاه داده مراجعه نماییم.
SELECT چیست ؟
دستور SELECT وسیلهای است که با کمک آن اطلاعات را از جدولهای پایگاه داده بازخوانی میکنیم. اطلاعات برگشت داده شده توسط این دستور ممکن است از یک جدول، چند جدول، Viewها، Stored Procedureها یا منابع دیگر اطلاعاتی که پایگاه داده به آن دسترسی دارد، خوانده شوند.
کوئری یا Query چیست ؟
دستوراتی که با زبان SQL نوشته میشوند تا تغییرات لازم را روی پایگاه داده انجام دهند، کوئری نامیده میشوند. کوئری در پایگاه داده تقریبا معادل عبارت اسکریپت در برنامهنویسی است. هرچند برخی سیستمهای پایگاه داده دارای قابلیت برنامهنویسی یا اسکریپت نویسی هم میباشند.
پیشنیازها
در این مقاله از پایگاه داده MySQL و رابط کاربری phpMyAdmin استفاده میکنیم. برای تست دستورات میتوانید از همین ابزارها یا ابزارهای دیگری که در دسترس دارید کمک بگیرید.
اگر با روش کارکرد پایگاه داده آشنایی ندارید، بهتر است ابتدا در این خصوص مقداری مطالعه کنید و سپس این مقاله را مطالعه نمایید.
جدولهای پایه برای خواندن اطلاعات
در این مقاله ما از دو جدول آزمایشی به نامهای students و classes استفاده میکنیم. ساختار این دو جدول به شکل تصویر زیر است:


همان طور که مشاهده میکنید در دو جدول بالا چهار دانش آموز و دو کلاس موجود است. هر دانش آموز با استفاده از کلید خارجی class_id در یک کلاس ثبت شده است.
خواندن اطلاعات از جدولها به صورت تکی
دستور SELECT در سادهترین شکل خود به صورت زیر است:
|
1 |
SELECT * FROM `نام جدول` |
برای مثال با دو دستور زیر اطلاعات جدولهای فوق را میتوانیم به صورت کامل و تک به تک بازخوانی کنیم:
|
1 2 3 4 5 |
-- 1 SELECT * FROM students; -- 2 SELECT * FROM classes; |
در سیستمهای پایگاه داده معمولا دو علامت خط تیره در ابتدای خط، آن خط را به حالت توضیحات تبدیل میکند.
اگر در Query ما چند دستور جداگانه وجود دارد، لازم است تا انتهای هر دستور را با نقطهویرگول «;» علامتگذاری کنیم.
هنگامی که قصد داریم نام جدولها و ستونهای جدولها را در Query بنویسیم، قراردادن علامت Back Quote یا «`» در ابتدا و انتهای نام اختیاری است. اگر نام جدول یا ستون از کلمات غیرمجاز در پایگاه داده باشد، استفاده از Back Quote الزامی خواهد بود:
|
1 2 3 4 5 |
-- 1 SELECT * FROM `students`; -- 2 SELECT * FROM `classes`; |
دو دستور بالا، تمامی ردیفهای دو جدول را مانند تصاویری که بالاتر مشاهده کردید، بازخوانی میکنند.
خواندن برخی از ستونها
به جای علامت * که معادل تمامی ستونهای جدول است میتوانیم نام برخی از ستونها را مقابل SELECT بنویسیم:
|
1 |
SELECT `fname`, `sname` FROM `students`; |
خواندن اطلاعات به صورت شرطی
اگر بخواهیم برخی ردیفهای یک جدول را با وجود یک شرط بازخوانی کنیم، از کلمه WHERE در انتهای کوئری استفاده میکنیم:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- دانش آموزی با شناسه ۱ SELECT * FROM `sutdents` WHERE `id` = 1; -- دانش آموزهایی با نام علی SELECT * FROM `sutdents` WHERE `fname` = 'علی'; -- دانشآموزانی که سنشان از ۱۶ سال بیشتر است SELECT * FROM `sutdents` WHERE `age` > 16; -- دانش آموزانی که در کلاس ۱ هستند SELECT * FROM `sutdents` WHERE `class_id` = 1; -- دانش آموزانی که در کلاس ۱ نیستند SELECT * FROM `sutdents` WHERE `class_id` <> 1; |
استفاده از شرطهای ترکیبی
گاهی ممکن است بخواهیم چند شرط را با هم ترکیب کنیم و بر اساس آنها نتایج مورد نظرمان را بازخوانی کنیم. این کار به طور عمده با دو عبارت AND و OR انجام میشود. AND برای وجود دو شرط به صورت همزمان و OR برای وجود یکی از دو شرط.
|
1 2 3 4 5 |
-- دانشآموزانی که ۱۶ یا ۱۷ سال دارند SELECT * FROM `sutdents` WHERE `age` = 16 OR `age` = 17; -- دانشآموزانی که سن آنها بیشتر از ۱۶ و کمتر از ۱۸ است SELECT * FROM `sutdents` WHERE `age` > 16 AND `age` < 18; |
با استفاده از پرانتز میتوانیم شرطهایی پیچیدهتر هم بنویسیم:
|
1 2 |
-- دانشآموزانی که سن آنها ۱۶ سال است یا بین ۱۸ و ۲۰ سال دارند SELECT * FROM `sutdents` WHERE `age` = 16 OR ( `age` > 18 AND `age` < 20 ); |
شرطهایی که میتوانید در SQL بنویسید بسیار گستردهتر از موارد بالا است. در این مقاله تا همین مقدار متوقف میشویم و به عملکردهای دیگر SELECT میپردازیم.
مرتب سازی نتایج
در صورت تمایل میتوانید از پایگاه داده بخواهید که نتایج دریافتی را قبل از ارسال، بر اساس فیلد یا فیلدهای مورد نظر شما مرتب کند:
|
1 2 3 4 5 |
-- دانش آموزانی که در کلاس ۱ هستند بر اساس نام خانوادگی مرتب شوند SELECT * FROM `sutdents` WHERE `class_id` = 1 ORDER BY `sname`; -- همه دانش آموزان بر اساس سن از بزرگ به کوچک مرتب شوند SELECT * FROM `sutdents` ORDER BY `age` DESC; |
مرتبسازی با استفاده از دستور ORDER BY به انجام میرسد. پس از نام فیلد میتوانید از عبارت DESC برای مرتبسازی معکوس استفاده کنید.
چنانچه بخواهیم مرتبسازی بر اساس دو فیلد انجام شود، میتوانیم نام چند فیلد را ذکر کنیم:
|
1 2 |
-- مرتبسازی ابتدا بر اساس سن و سپس بر اساس نام خانوادگی SELECT * FROM `sutdents` ORDER BY `age`, `sname`; |
هنگامی که نام چند فیلد را در مرتبسازی درج میکنیم، اگر در ردیف در فیلد اول یکسان باشند، بر اساس فیلد دوم مرتب میشوند و اگر فیلد اول مقدار متفاوتی داشته باشند، فیلد دوم در نظر گرفته نمیشود.
محدود کردن تعداد نتایج بازگشتی
اگر تعداد ردیفهای جدول شما زیاد باشد، خواندن حجم زیادی از اطلاعات به صورت یکباره میتواند مشکلاتی به همراه داشته باشد. در این شرایط اطلاعات معمولا به صورت صفحه به صفحه و در هر صفحه به تعداد کمتری بازخوانی میشوند. برای محدود کردن تعداد نتایج بازگشتی از دستور LIMIT به شکل زیر استفاده میکنیم:
|
1 |
SELECT * FROM `sutdents` ORDER BY `lname` LIMIT 10; |
دستور LIMIT در مثال بالا ۱۰ ردیف از جدول دانشآموزان را برگشت میدهد. در فراخوانی دوم برای برگشت دادن ۱۰ دانشآموز دوم به شکل زیر عمل میکنیم:
|
1 |
SELECT * FROM `sutdents` ORDER BY `lname` LIMIT 10, 10; |
در مثال بالا ابتدا ۱۰ ردیف را نادیده میگیریم و سپس ۱۰ ردیف دوم را بازخوانی میکنیم.
جلوگیری از برگشت ردیفهای تکراری
هنگامی که قصد صفحهبندی اطلاعات با استفاده از LIMIT را داریم برای جلوگیری از نمایش ردیفهای تکراری در فراخوانیهای پیدرپی لازم است تا همیشه از ORDER BY در کنار آن استفاده کنیم. اگر فیلد مورد نظر ما برای مرتبسازی منحصر به فرد باشد، مشکلی رخ نمیدهد ولی همچنان اگر فیلد ما برای مثال «نام خانوادگی» امکان تکراری بودن داشته باشد، میتواند باعث نمایش نتایج تکراری در صفحات مختلف شود. به همین دلیل بهتر است از فیلد شناسه هم به شکل زیر در کنار فیلد اصلی مرتبسازی کمک بگیرید:
|
1 |
SELECT * FROM `sutdents` ORDER BY `lname`, `id` LIMIT 10; |
همان طور که میبینید مرتبسازی ابتدا با فیلد lname و سپس با id انجام میشود تا به طور کامل از برگشت ردیفهای تکراری در صفحات پی در پی جلوگیری شود.
بهینهسازی LIMIT
هنگامی که محتوای جدول شما و تعداد صفحات شما بسیار زیاد باشد، لازم است تا دستور SELECT خود را بهینهسازی کنید. چون برای فراخوانی اطلاعات در صفحهی آخر، تمام ردیفها از ابتدا تا انتها پیمایش میشوند و بعد اطلاعات آن صفحه به نمایش درمیآید. در وضعیت حداقلی باید مطمئن شوید که فیلدهای ORDER BY شما روی ستونهای Index شده اجرا میشوند و همچنین تعداد ستونهای مرتبسازی در کمترین مقدار ممکن است.
شکلهای دیگر دستور LIMIT
شکل فراخوانی دستور LIMIT در سیستمهای پایگاه دادهی مختلف یکسان نیست. اگر از سیستمی به جز MySQL استفاده میکنید، انواع دیگر فراخوانی را اینجا میتوانید ببینید.
سرعت مرتبسازی و جستجو
هنگامی که تعداد ردیفهای موجود در جدول شما زیاد نباشد، مرتبسازی و جستجو با استفاده از روشهای بالا به سرعت انجام میشود. ولی اگر تعداد ردیفها افزایش پیدا کند، اجرای کوئریها میتواند بسیار سنگین و زمانبر باشد. چون لازم است تمامی اطلاعات از دیسک سخت خوانده شود و مرتبسازی یا جستجو شوند.
برای رفع این مشکل لازم است تا روی ستونهایی که بنا است در حجم زیاد جستجو شوند یا مرتبسازی شوند، Index گذاری شود. روش درج Index و نکات مربوط به آن خارج از موضوع این مقاله است و میبایست در مورد آن مطالعه نمایید.
علاوه بر جستجو و مرتبسازی، در JOIN روی کلید خارجی نیز لازم است تا از Index استفاده کنیم. در ادامه و در بخش JOINها در این مورد مطالب بیشتری را مرور خواهیم کرد.
JOIN ها - خواندن اطلاعات از چند جدول
در قسمتهای قبلی اطلاعات فقط از یک جدول خوانده شدند. با استفاده از JOINها میتوانیم اطلاعات چند جدول را با هم ترکیب کنیم و آنها را به صورت یک جدول جدید بازخوانی نماییم.
انواع JOIN ها
- نوع داخلی یا INNER
- نوع خارجی یا OUTER
نوع داخلی یا INNER نوعی از JOIN است که نتایج از جدول اول و دوم هنگامی که هر دو طرف موجود باشند، برگردانده میشوند. نوع خارجی یا OUTER حالتی است که نتایج بازگشتی میتواند تنها از یک جدول باشند و جدول دوم میتواند خالی باشد.
با استفاده از مثالها در ادامه این دو نوع JOIN را بهتر متوجه خواهید شد.
INNER JOIN
اگر بخواهیم نام تمامی دانشآموزان به همراه نام کلاسی که در آن ثبت شدهاند را بازخوانی کنیم به شکل زیر از JOIN داخلی استفاده میکنیم:
|
1 2 |
SELECT fname, sname, classes.name FROM students INNER JOIN classes ON students.class_id = classes.id; |

نکاتی در مورد INNER JOIN
- با استفاده از دستور ON مشخص میکنیم که ردیفهای جدول اول با چه شرطی به جدول دوم متصل میشوند. در مثال بالا، ردیفهایی از جدول classes که مربوط به هر دانشآموز بودند را به آن متصل کردیم.
- برای خواندن ستونهای دلخواه از جدولها، اگر نام ستونها در دو جدول تکراری نیست، میتوانیم تنها نام ستون را مقابل SELECT بنویسیم. برای مثال fname و sname فقط در جدول اول وجود دارند. ولی اگر بخواهیم ستون id دانشآموز را در خروجی درج کنید، لازم است تا قبل از id نام جدول students را هم ذکر کنیم: students.id یا classes.id
- هنگامی که از JOIN استفاده میکنیم، بهتر است همیشه نام ستونهای دلخواه را به صورت صریح بنویسیم و از علامت * استفاده نکنیم. زیرا در صورت مشابه بودن نام ستونها، نتایج بازگشتی ممکن است به درستی قابل استفاده نباشند.
تغییر نام جدولها و ستونها
اگر نام ستونها در دو جدول تکراری باشند و به مقدار هر دو فیلد در دو جدول نیاز داشته باشیم، میتوانیم به شکل زیر نام آنها را تغییر دهیم:
|
1 2 |
SELECT s.id AS s_id, s.fname, sname, c.id AS c_id, c.name FROM students s INNER JOIN classes c ON s.class_id = c.id |

همان طور که در کدها و تصویر مشاهده میکنید، نام جدولها و نام ستونها را به صورت موقتی تغییر دادیم تا بتوانیم از همه اطلاعات در خروجی استفاده کنیم.
فیلد شناسه جدول students به s_id و فیلد شناسه جدول classes به c_id تغییر کرده است.
JOIN خارجی چپ و راست
اتصال جدولها به صورت خارجی ممکن است به شکل چپ LEFT JOIN یا راست RIGHT JOIN باشد.
- LEFT JOIN حالتی است که همیشه ردیفهای جدول اول در خروجی موجود هستند. حتی اگر ردیف متناظری در جدول دوم موجود نباشد.
- RIGHT JOIN حالتی است که همیشه ردیفهای جدول دوم در خروجی موجود هستند. حتی اگر ردیف متناظری در جدول اول موجود نباشد.
کاربردهای JOIN خارجی
برای اینکه کاربرد جوین خارجی را بهتر متوجه شوید، یک دانش آموز جدید که در کلاسی ثبت نشده به جدول اضافه میکنیم و مقدار class_id آن را معادل صفر قرار میدهیم. همچنین یک کلاس جدید اضافه میکنیم که هیچ دانش آموزی در آن ثبت نشده است:


اکنون با استفاده از دستور زیر میتوانیم تمام دانشآموزان و کلاسهایشان( حتی اگر کلاسی نداشته باشند ) را فهرست کنیم:
|
1 2 |
SELECT s.*, c.name FROM students s LEFT JOIN classes c ON s.class_id = c.id |

و با استفاده از دستور زیر، تمام کلاسها و دانش آموزان آنها را ( حتی اگر دانشآموزی نداشته باشند ) فهرست میکنیم:
|
1 2 |
SELECT c.*, s.fname, s.sname FROM students s RIGHT JOIN classes c ON s.class_id = c.id |

در حالتهای بالا اگر از JOIN داخلی استفاده کنیم، ردیفهایی که مقابل آنها مقدار NULL مشاهده میشود، از خروجی حذف میشوند و تنها ردیفهایی که در هر دو جدول موجود باشند برگردانده میشوند.
گروهبندی نتایج با GROUP BY
یکی از نیازهای متداول هنگام دریافت اطلاعات از پایگاه داده، گروهبندی آنها است. برای مثال هنگامی که بخواهیم میانگین نمرات هر دانشآموز را در درسهای مختلف به دست آوریم یا تعداد دانشآموزانی که در هر کلاس هستند را بشماریم.
در مثالهای بالا، برای میانگین نمرات، لازم است تا نمرات هر دانشآموز با هم به یک گروه تبدیل شوند و میانگین هر گروه به صورت مجزا محاسبه شود.
برای روشنتر شدن موضوع، روی دادههای مثال بالا، تعداد دانشآموزان هر کلاس را میشماریم:
|
1 2 3 |
SELECT `classes`.`name`, count( students.id ) FROM `classes` inner join `students` on students.class_id = classes.id group by `classes`.`id` |
اجرای دستور فوق، نتیجهی زیر را برمیگرداند:
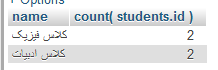
همانطور که مشاهده میکنید، تعداد دانشآموزان هر کلاس با استفاده از دستور count محاسبه و نمایش داده شده است. تابع count یک تابع Aggregate است که در ادامه بیشتر با آن آشنا میشویم.
راهنمای استفاده از دستور GROUP BY
برای استفاده از دستور GROUP BY همان طور که در مثال فوق قابل مشاهده است، یک فیلد منحصر به فرد که نتایج میبایست بر اساس آن گروهبندی شوند لازم است. این فیلد معمولا فیلد ID است که منحصر به فرد است. در نمونه بالا از ID کلاس برای گروهبندی استفاده کردهایم. امکان استفاده از نام کلاس نیز وجود داشت ولی در صورتی که نام دو کلاس به اشتباه شبیه هم وارد شوند، نتایج قابل استفاده نخواهند بود.
توابع Aggregate
دستوراتی که روی گروهی از نتایج عمل میکنند، اصطلاحا دستورات Aggregate نامیده میشوند. فهرست توایع Aggregate در سیستمهای مختلف پایگاه داده نیز متفاوت است. همچنین عملکرد این سیستمها روی شکل برگشت دادن نتایج نیز تفاوتهایی با یکدیگر دارد که بسته به نوع سیستم، میبایست آشنایی کافی را با آن به دست آورید.
- فهرست توابع Aggregate در SQL Server
- فهرست توابع Aggregate در MySQL
- فهرست توابع Aggregate در Oracle
- فهرست توابع Aggregate در SQLite
توابعی که معمولا بیشتر مورد استفاده قرار میگیرند و در تمامی سیستمهای پایگاه داده نیز موجود هستند عبارتند از:
- COUNT
- AVG
- SUM
- MIN
- MAX
فیلدهایی که در نتایج قابل مشاهده هستند
هنگام گروهبندی نتایج لازم است تا فیلدها را به صورت دقیق برای نمایش مشخص کنید. فیلدها در یکی از دو صورت زیر در خروجی قابل نمایش هستند:
- هنگامی که فیلد مورد نظر گروهبندی شده باشد( اینجا ID کلاس )
- هنگامی که فیلد مورد نظر با یک تابع Aggregate محاسبه شود.
اگر به خوبی دقت کرده باشید، متوجه میشوید که ما از فیلد نام کلاس استفاده کردیم در حالی که هیچ کدام از شرایط فوق را ندارد. علت این است که سیستم پایگاه داده MySql به ما اجازه میدهد فیلدهای دیگر را هم در فهرست نتایج بیاوریم. ولی در حالت استاندارد لازم بود که مقابل دستور GROUP BY، نام کلاس هم به عنوان فیلد دوم اضافه شود تا با خطایی مواجه نشویم.
ترکیب با JOIN
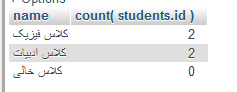
نکتهای که در فهرست فوق قابل مشاهده است، عدم نمایش کلاس «کلاس خالی» در فهرست نتایج است. این موضوع مستقیم با گروهبندی ارتباط ندارد و به دلیل استفاده از JOIN این اتفاق افتاده است. با تغییر حالت JOIN به OUTER میتوانیم نام کلاس خالی را هم در فهرست مشاهده کنیم:
|
1 2 3 |
SELECT `classes`.`name`, count( students.id ) FROM `classes` left join `students` on students.class_id = classes.id group by `classes`.`id` |
ایجاد شرط روی گروه
به طور کلی فیلتر کردن نتایج با استفاده از دستور WHERE که بالاتر گفته شد، قابل انجام است. علاوه بر WHERE، هنگام گروهبندی نتایج، یک دستور دیگر با نام HAVING قابل استفاده است:
|
1 2 3 |
SELECT `classes`.`name`, count( students.id ) FROM `classes` left join `students` on students.class_id = classes.id group by `classes`.`id` having count( students.id ) < 2 |
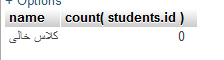
استفاده از دستورات WHERE و HAVING در بسیاری از موارد به جای هم امکانپذیر است. تفاوت اصلی که این دو دستور با یکدیگر دارند و هنگام بهینهسازی تخصصی پایگاه داده نیاز است تا به آن توجه شود، این است که WHERE پیش از انجام محاسبات نتایج را فیلتر میکند و HAVING پس از انجام محاسبات، نتایج اضافی را از خروجی حذف میکند. بنابراین تا جایی که ممکن باشد بهتر است از WHERE استفاده شود.
ادامه دارد...
بسیار عالی و کاربردی بود. سپاس